SVCODEC:
A STREAMING VARIABLE NEURAL SPEECH CODEC
Huaifeng Zhang 1, Peifei Wu1, Guigeng Li1, Yuan An1, Hao Zhang1*,
1College of Electronic Engineerin, Ocean University of China, QingDao, 266100, China
Abstract.
This page is for research demonstration purposes only.
SVCODEC Model Architecture
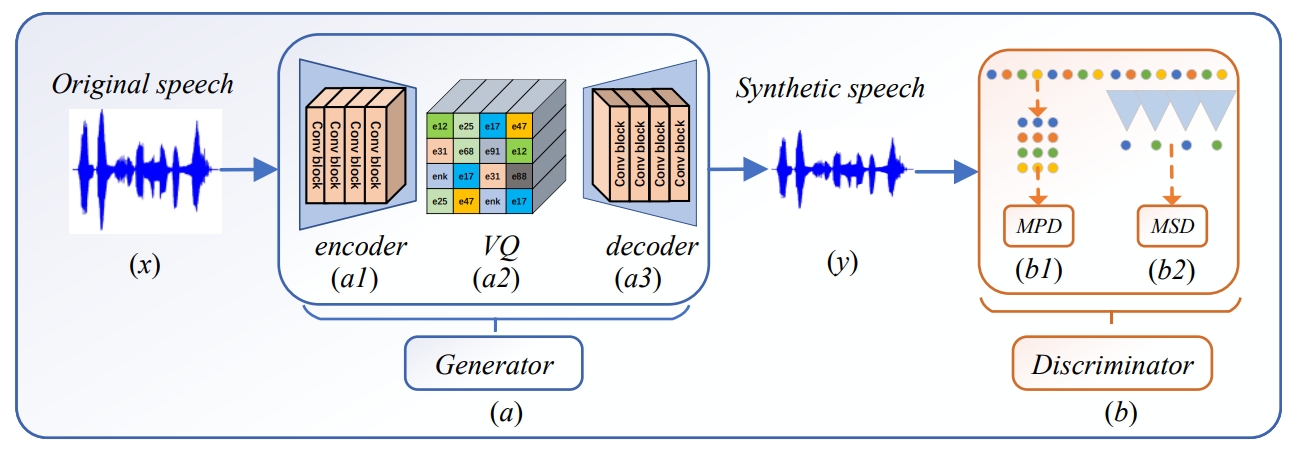
Part I:The generator (a) of the GAN network which consists of encoder (a1), vector quantizer (a2) and decoder (a3) and used to generate synthesized speech (y) which will be input to the discriminator (b) of the GAN network. Part II: The efficient discriminator (b), consisting of a multi-period discriminator (b1) and a multi-scale discriminator (b2).
Subjective Experimental Results
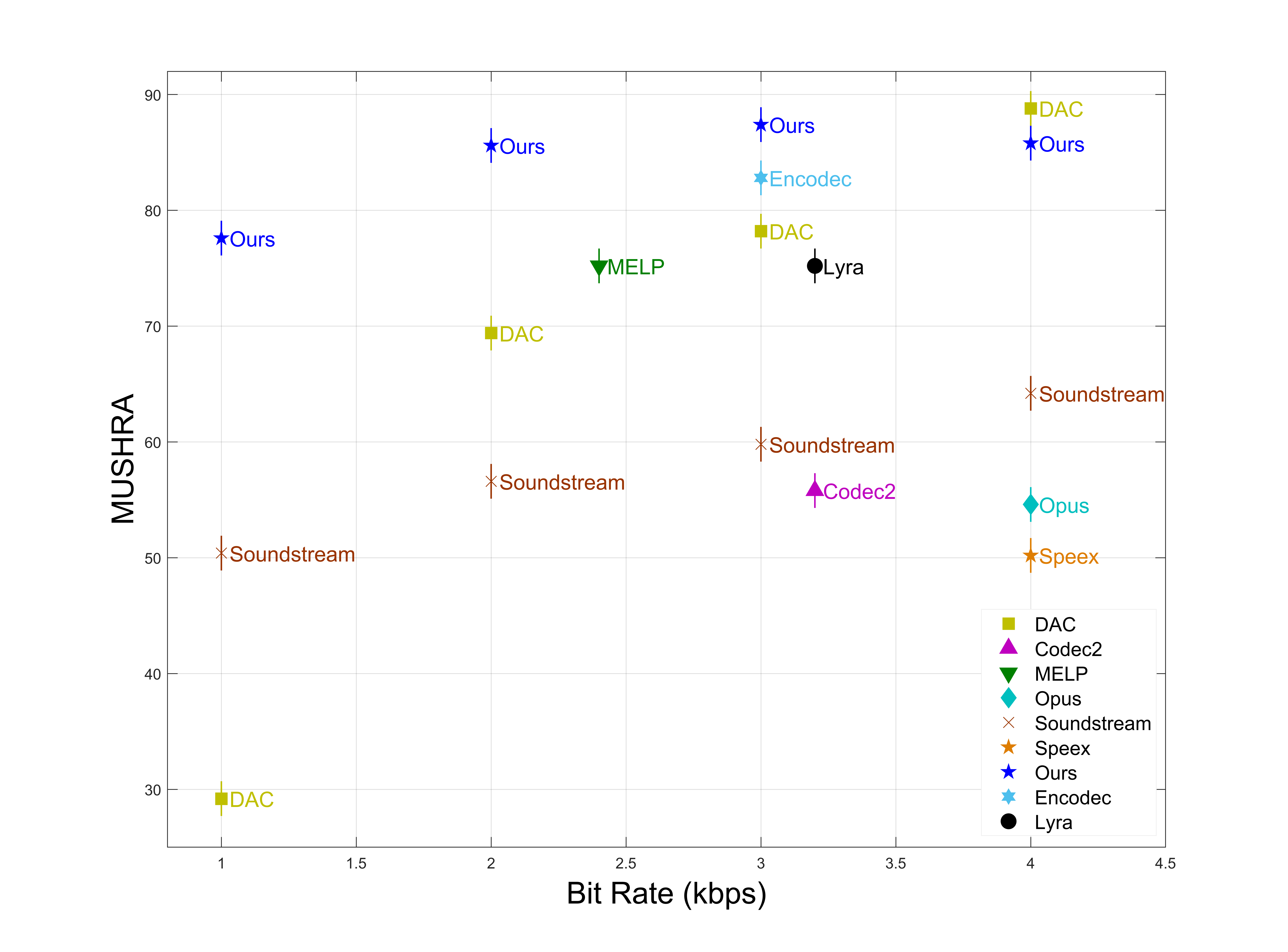
When the bit rate is the same or similar, SVCODEC holds an absolute advantage in MUSHRA score
Objective Experimental Results
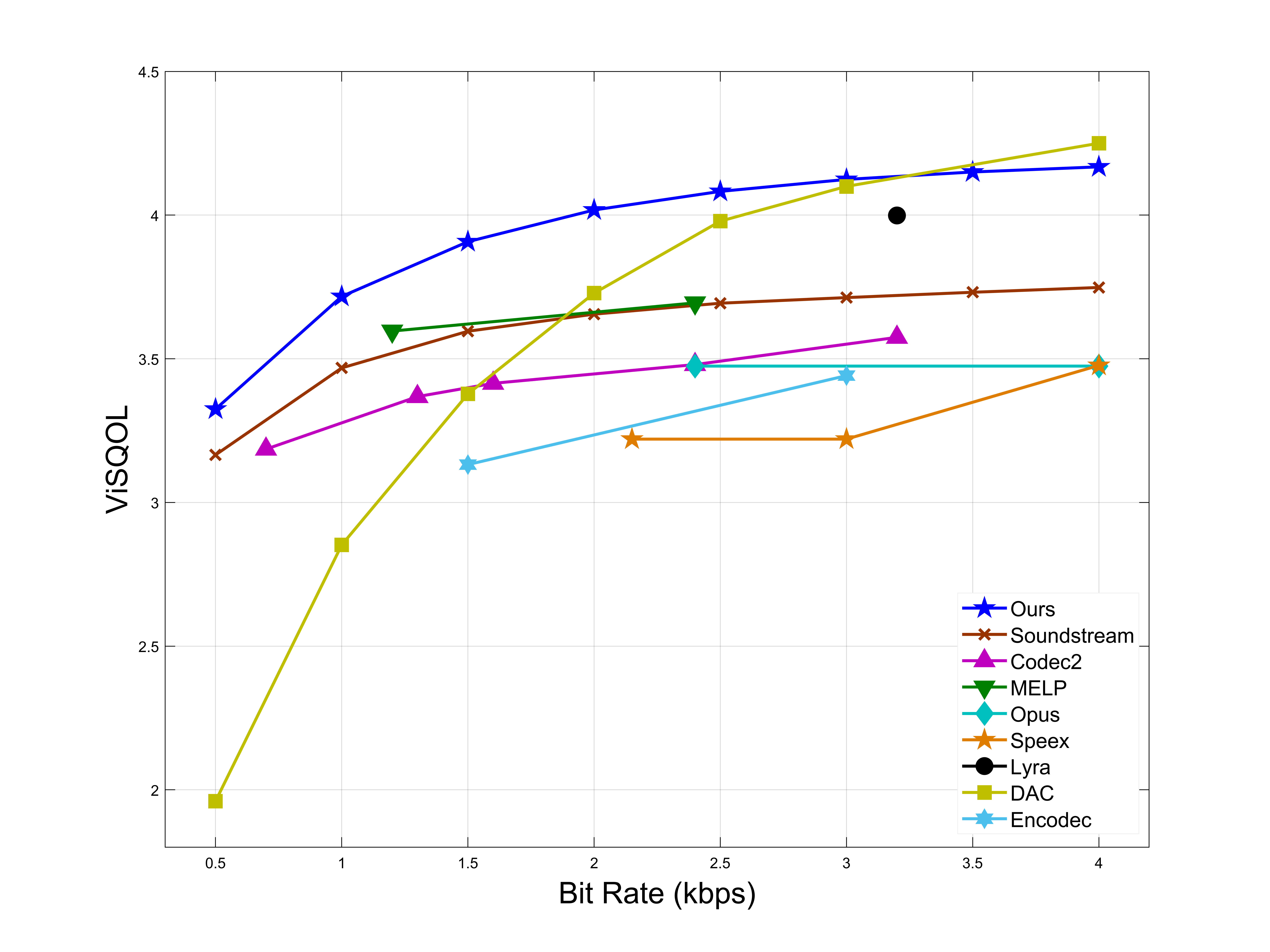
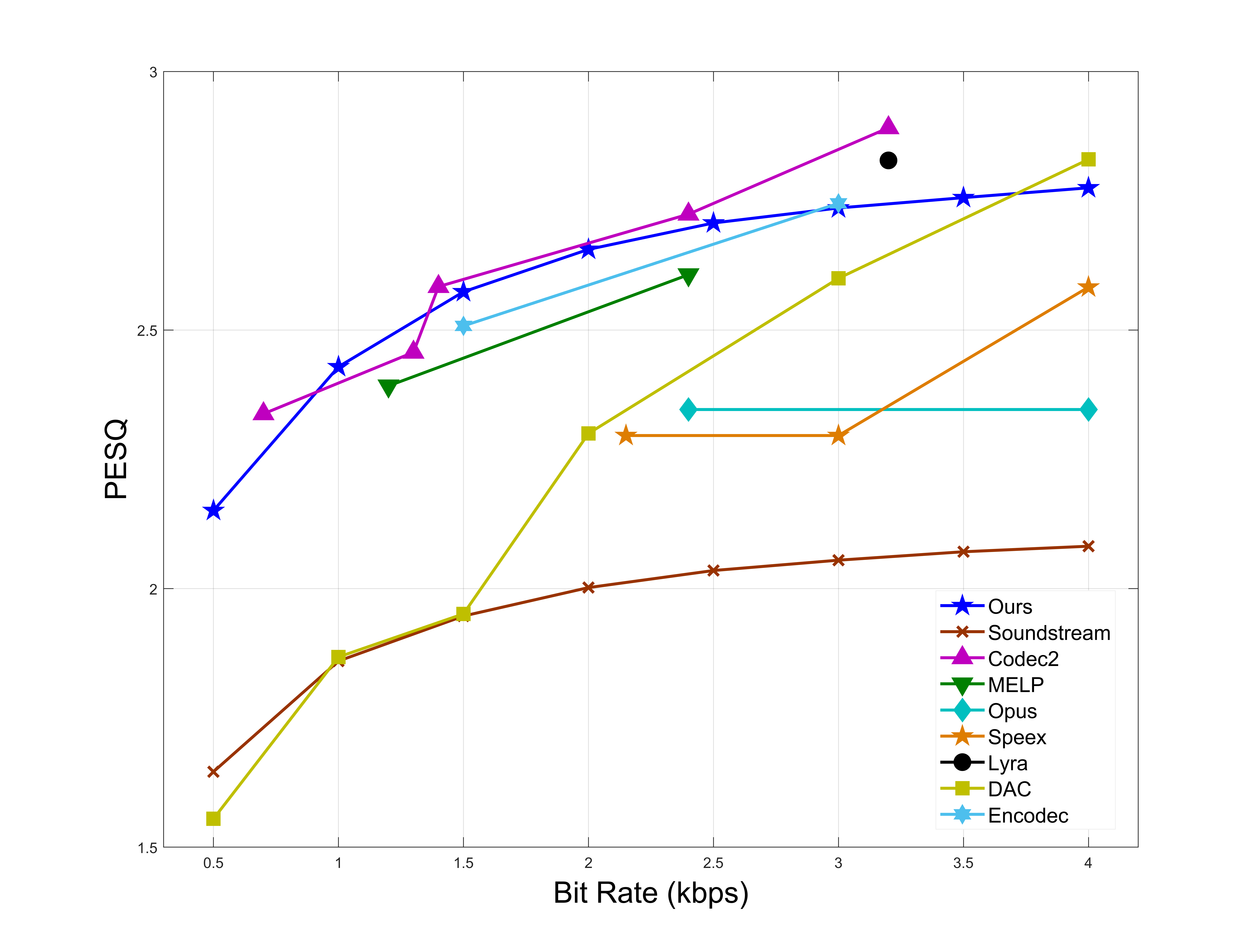
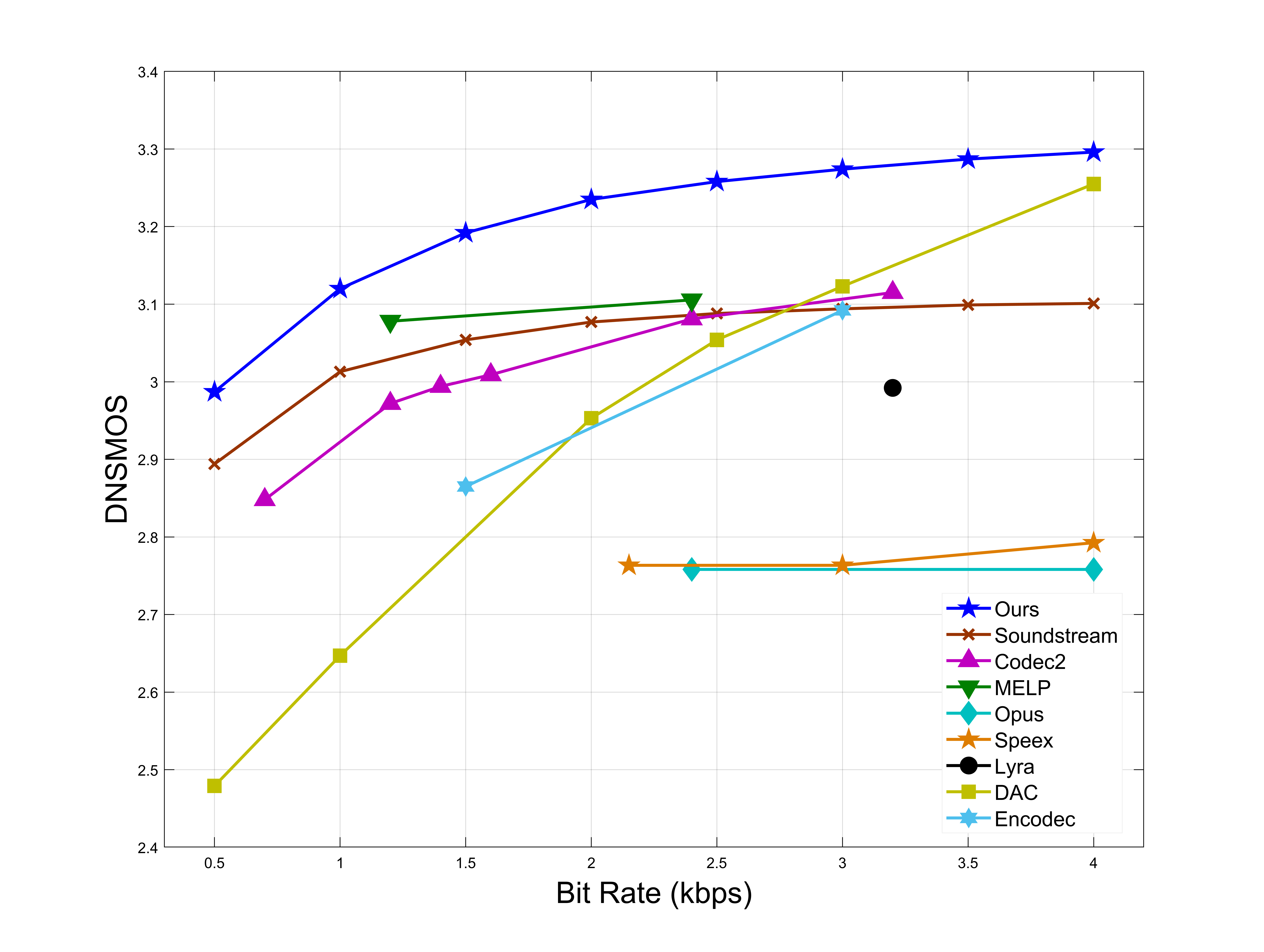
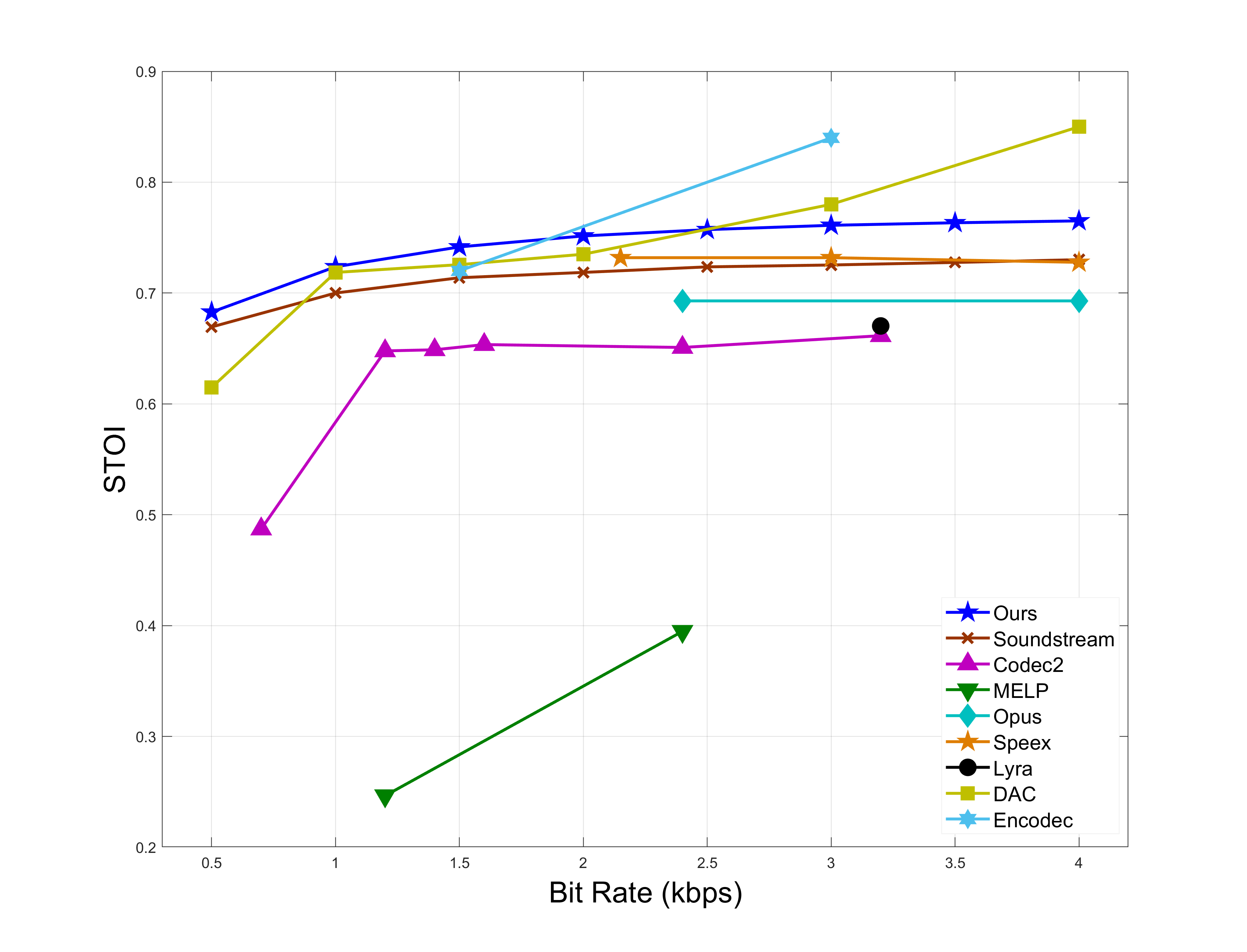
In the same code rate range, SVCODEC has higher ViSQOL, PESQ, DNSMOS, and STOI scores.
Original Input Speech from LibriSpeech
| Label | Gender | Speaker | Text | Speech |
|---|---|---|---|---|
| Sample1 | Male | Paul-Gabriel Wiener | HE BEGAN A CONFUSED COMPLAINT AGAINST THE WIZARD WHO HAD VANISHED BEHIND THE CURTAIN ON THE LEFT | |
| Sample2 | Male | Brad Bush | SATURDAY AUGUST FIFTEENTH THE SEA UNBROKEN ALL ROUND NO LAND IN SIGHT | |
| Sample3 | Male | Taylor Burton-Edward | OUT IN THE WOODS STOOD A NICE LITTLE FIR TREE | |
| Sample4 | Female | Nikolle Doolin | ALSO A POPULAR CONTRIVANCE WHEREBY LOVE MAKING MAY BE SUSPENDED BUT NOT STOPPED DURING THE PICNIC SEASON | |
| Sample5 | Female | Rachelellen | SOMEHOW OF ALL THE DAYS WHEN THE HOME FEELING WAS THE STRONGEST THIS DAY IT SEEMED AS IF SHE COULD BEAR IT NO LONGER |
Output Speech of SVCODEC (Ours)
| Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| 0.5kbps | |||||
| 1kbps | |||||
| 1.5kbps | |||||
| 2kbps | |||||
| 2.5kbps | |||||
| 3kbps | |||||
| 3.5kbps | |||||
| 4kbps |
Output Speech of DAC
| Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| 0.5kbps | |||||
| 1kbps | |||||
| 1.5kbps | |||||
| 2kbps | |||||
| 2.5kbps | |||||
| 3kbps | |||||
| 4kbps |
Output Speech of Encodec
| Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| 1.5kbps | |||||
| 3kbps |
Output Speech of SoundStream
| Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| 0.5kbps | |||||
| 1kbps | |||||
| 1.5kbps | |||||
| 2kbps | |||||
| 2.5kbps | |||||
| 3kbps | |||||
| 3.5kbps | |||||
| 4kbps |
Output Speech of Codec2
| Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| 0.7kbps | |||||
| 1.2kbps | |||||
| 1.6kbps | |||||
| 2.4kbps | |||||
| 3.2kbps |
Output Speech of MELP
| Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| 1.2kbps | |||||
| 2.4kbps |
Output Speech of Opus
| Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| 1.2kbps | |||||
| 2.4kbps | |||||
| 4kbps | |||||
| 6kbps |
Output Speech of Speex
| Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| 1.2kbps | |||||
| 3kbps | |||||
| 4kbps | |||||
| 6kbps |
Output Speech of Lyra
| Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| 3.2kbps | |||||
| 6kbps |
Multiple Comparisons
Similar output quality with lower bitrate.| Model | Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|---|
| Speex | 6kbps | |||||
| Opus | 6kbps | |||||
| Lyra | 6kbps | |||||
| SVCODEC | 4kbps |
Similar bitrate (1.2kbps) with higher output quality.
| Model | Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|---|
| Speex | 1.2kbps | |||||
| Opus | 1.2kbps | |||||
| MELP | 1.2kbps | |||||
| Codec2 | 1.2kbps | |||||
| DAC | 1kbps | |||||
| SoundStream | 1kbps | |||||
| SVCODEC | 1kbps |
Similar bitrate (2kbps) with higher output quality.
| Model | Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|---|
| DAC | 1.5kbps | |||||
| Encodec | 1.5kbps | |||||
| SoundStream | 1.5kbps | |||||
| SVCODEC | 1.5kbps |
Similar bitrate (2kbps) with higher output quality.
| Model | Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|---|
| DAC | 2kbps | |||||
| SoundStream | 2kbps | |||||
| SVCODEC | 2kbps |
Similar bitrate (2.4kbps) with higher output quality.
| Model | Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|---|
| Opus | 2.4kbps | |||||
| MELP | 2.4kbps | |||||
| Codec2 | 2.4kbps | |||||
| DAC | 2.5kbps | |||||
| SoundStream | 2.5kbps | |||||
| SVCODEC | 2.5kbps |
Similar bitrate (3kbps) with higher output quality.
| Model | Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|---|
| Lyra | 3.2kbps | |||||
| Speex | 3kbps | |||||
| Codec2 | 3.2kbps | |||||
| DAC | 3kbps | |||||
| Encodec | 3kbps | |||||
| SoundStream | 3kbps | |||||
| SVCODEC | 3kbps |
Similar bitrate (4kbps) with higher output quality.
| Model | Bitrate | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|---|
| Speex | 4kbps | |||||
| Opus | 4kbps | |||||
| DAC | 4kbps | |||||
| SoundStream | 4kbps | |||||
| SVCODEC | 4kbps |
Comparision Results on LibriSpeech
| Model | Bit Rate(kbps) | DNSMOS↑ | PESQ↑ | STOI↑ | ViSQOL↑ |
|---|---|---|---|---|---|
| Speex | 1.2 | 2.76 | 2.30 | 0.73 | 3.22 |
| Opus | 1.2 | 2.76 | 2.35 | 0.69 | 3.47 |
| MELP | 1.2 | 3.11 | 2.61 | 0.25 | 3.60 |
| Codec2 | 1.2 | 2.97 | 2.57 | 0.65 | 3.36 |
| DAC | 1 | 2.56 | 1.87 | 0.72 | 2.85 |
| SoundStream | 1 | 3.01 | 1.86 | 0.70 | 3.47 |
| SVCODEC | 1 | 3.12 | 2.43 | 0.72 | 3.72 |
| Encodec | 1.5 | 2.86 | 2.51 | 0.72 | 3.13 |
| DAC | 1.5 | 2.65 | 1.95 | 0.73 | 3.38 |
| SoundStream | 1.5 | 3.05 | 1.95 | 0.71 | 3.60 |
| SVCODEC | 1.5 | 3.19 | 2.57 | 0.74 | 3.91 |
| DAC | 2 | 2.95 | 2.30 | 0.74 | 3.73 |
| SoundStream | 2 | 3.08 | 2.00 | 0.72 | 3.66 |
| SVCODEC | 2 | 3.24 | 2.66 | 0.75 | 4.02 |
| Opus | 2.4 | 2.76 | 2.35 | 0.69 | 3.47 |
| MELP | 2.4 | 3.11 | 2.61 | 0.39 | 3.69 |
| Codec2 | 2.4 | 3.08 | 2.72 | 0.65 | 3.48 | DAC | 2.5 | 3.05 | 2.42 | 0.75 | 3.98 |
| SoundStream | 2.5 | 3.09 | 2.04 | 0.72 | 3.69 |
| SVCODEC | 2.5 | 3.26 | 2.71 | 0.76 | 4.08 |
| Lyra | 3.2 | 2.99 | 2.83 | 0.67 | 4.00 |
| Codec2 | 3.2 | 3.12 | 2.89 | 0.66 | 3.57 |
| Speex | 3 | 2.76 | 2.30 | 0.73 | 3.22 |
| Encodec | 3 | 3.09 | 2.75 | 0.84 | 3.44 |
| DAC | 3 | 3.12 | 2.60 | 0.78 | 4.10 |
| SoundStream | 3 | 3.09 | 2.06 | 0.73 | 3.71 |
| SVCODEC | 3 | 3.27 | 2.74 | 0.76 | 4.12 |
| SoundStream | 3.5 | 3.10 | 2.07 | 0.73 | 3.73 |
| SVCODEC | 3.5 | 3.29 | 2.76 | 0.76 | 4.15 |
| Speex | 4 | 2.80 | 2.58 | 0.73 | 3.48 |
| Opus | 4 | 2.76 | 2.35 | 0.69 | 3.47 |
| DAC | 4 | 3.26 | 2.83 | 0.85 | 4.25 |
| SoundStream | 4 | 3.10 | 2.08 | 0.73 | 3.75 |
| SVCODEC | 4 | 3.30 | 2.78 | 0.77 | 4.17 |
SVCODEC Model Variants
| Model | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| SVCODEC | |||||
| SVCODEC V1 | |||||
| SVCODEC V2 |
Comparison of model variants at 4kbps.
| Model | Periods | DNSMOS↑ | PESQ↑ | STOI↑ | ViSQOL↑ |
|---|---|---|---|---|---|
| SVCODEC | [2 3 5 7 11] | 3.296 | 2.775 | 0.765 | 4.17 |
| SVCODEC v1 | [2 3 5 7] | 3.275 | 2.747 | 0.756 | 4.13 |
| SVCODEC v2 | [2 3 5 7 11 13] | 3.249 | 2.729 | 0.627 | 4.12 |
SVCODEC Model Generalization
| Dataset | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| LJSpeech | |||||
| LibriTTS | |||||
| Aishell-1 |
Comparison on generalization of SVCODEC
| Dataset | DNSMOS↑ | PESQ↑ | STOI↑ | ViSQOL↑ |
|---|---|---|---|---|
| Aishell-1 | 3.09 | 2.42 | 0.65 | 4.08 |
| LibriSpeech | 3.30 | 2.78 | 0.77 | 4.17 |
| LibriTTS | 3.18 | 2.76 | 0.77 | 4.11 |
| LJSpeech | 3.43 | 2.61 | 0.74 | 4.32 |